
Tomcat7 clustering and session replication in AWS
This was a POC for Tomcat clustering and session replication in AWS. It has been set up and tested on a pair of EC2 instances (ip-172-31-13-11 and ip-172-31-13-12) deployed in one of our test VPC’s. Since the multicast between the availability zones is still not possible in AWS we need to use the static cluster membership. The traffic for the private subnet is unrestricted for the Security Group the instances belong to.
Configuration
Tomcat
We configure the Cluster element in the tomcat’s server.xml file on both nodes.
<Cluster className="org.apache.catalina.ha.tcp.SimpleTcpCluster" channelStartOptions="3" channelSendOptions="8">
<Manager className="org.apache.catalina.ha.session.DeltaManager"
expireSessionsOnShutdown="false"
notifyListenersOnReplication="true"/>
<Channel className="org.apache.catalina.tribes.group.GroupChannel">
<!--<Membership className="org.apache.catalina.tribes.membership.McastService"
address="228.0.0.4"
port="45564"
frequency="500"
dropTime="3000"/>-->
<Receiver className="org.apache.catalina.tribes.transport.nio.NioReceiver"
address="auto"
port="4000"
autoBind="100"
selectorTimeout="5000"
maxThreads="6"/>
<Interceptor className="org.apache.catalina.tribes.group.interceptors.StaticMembershipInterceptor">
<!--<Member className="org.apache.catalina.tribes.membership.StaticMember" port="4000" securePort="-1" host="ip-172-31-13-11" domain="publish-cluster" uniqueId="{10,0,10,109}"/>-->
<Member className="org.apache.catalina.tribes.membership.StaticMember" port="4000" securePort="-1" host="ip-172-31-13-12" domain="publish-cluster" uniqueId="{10,0,10,227}"/>
</Interceptor>
<Sender className="org.apache.catalina.tribes.transport.ReplicationTransmitter">
<Transport className="org.apache.catalina.tribes.transport.nio.PooledParallelSender"/>
</Sender>
<Interceptor className="org.apache.catalina.tribes.group.interceptors.TcpPingInterceptor"/>
<Interceptor className="org.apache.catalina.tribes.group.interceptors.TcpFailureDetector"/>
<Interceptor className="org.apache.catalina.tribes.group.interceptors.MessageDispatch15Interceptor"/>
</Channel>
<Valve className="org.apache.catalina.ha.tcp.ReplicationValve" filter=""/>
<Valve className="org.apache.catalina.ha.session.JvmRouteBinderValve"/>
<!--<Deployer className="org.apache.catalina.ha.deploy.FarmWarDeployer"
tempDir="/tmp/war-temp/"
deployDir="/tmp/war-deploy/"
watchDir="/tmp/war-listen/"
watchEnabled="false"/>-->
<ClusterListener className="org.apache.catalina.ha.session.JvmRouteSessionIDBinderListener"/>
<ClusterListener className="org.apache.catalina.ha.session.ClusterSessionListener"/>
</Cluster>
Some points to note in the above configuration that are different from the default one:
- We have commented out the multicast
McastServiceelement since we don’t need it (no multicast possible in AWS) - We add
channelStartOptions="3"to the Cluster element to disable the multicast (even when not explicitly configured, the multicast service is enabled by default) - We set
channelSendOptions="8"which means asynchronous session replication, for synchronous mode we need to set this option to 4 - We add the
StaticMembershipInterceptorclass and specifying the other static members of the cluster (the local host Member line is commented out, we don’t want the local host adding it self to the cluster) - We add
TcpPingInterceptorinterceptor that pings other nodes so that all nodes can recognize when other nodes have left the cluster (preventing the session replication to brake down when nodes are removed and re-introduced)
Additionally I have set the jvmRoute value of the Engine element on each node (tomcat1 and tomcat2) so I can easily distinguish the sessions as this value will be appended to each session created (each session will have .tomcat1 and .tomcat2 appended). This is also useful in case of Apache load balancer in front with mod_jk or mod_proxy since the tomcat cookies will also have the above value appended (JSESSIONID=xxxx.tomcat1 and JSESSIONID=xxxx.tomcat2).
<Engine name="Catalina" defaultHost="localhost" jvmRoute="tomcat1">
Application
I have used the Manager application to test the session replication. I deployed the app in $CATALINA_BASE/webapps and set the context file:
root@ip-172-31-13-11:~# vi /etc/tomcat7/Catalina/localhost/manager.xml
<Context privileged="true" antiResourceLocking="false"
docBase="${catalina.base}/webapps/manager" distributable="true">
<Valve className="org.apache.catalina.valves.RemoteAddrValve"
allow="172\.31\.13\..*" />
</Context>
and to cluster it we add the <distributable/> tag inside it’s web.xml file, /var/lib/tomcat7/webapps/manager/WEB-INF/web.xml, right at the end before the </web-app> tag.
Runtime
After that we restart the servers we can see the cluster startup and session replication messages that look as follows on ip-172-31-13-11:
06/11/2013 9:55:47 PM org.apache.catalina.ha.tcp.SimpleTcpCluster memberAdded
INFO: Replication member added:org.apache.catalina.tribes.membership.MemberImpl[tcp://ip-172-31-13-12:4000,ip-172-31-13-12,4000, alive=0, securePort=-1, UDP Port=-1, id={0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 }, payload={}, command={}, domain={112 117 98 108 105 115 104 45 99 ...(15)}, ]
06/11/2013 9:56:14 PM org.apache.catalina.ha.session.DeltaManager startInternal
INFO: Register manager localhost#/manager to cluster element Engine with name Catalina
06/11/2013 9:56:14 PM org.apache.catalina.ha.session.DeltaManager startInternal
INFO: Starting clustering manager at localhost#/manager
06/11/2013 9:56:14 PM org.apache.catalina.tribes.io.BufferPool getBufferPool
INFO: Created a buffer pool with max size:104857600 bytes of type:org.apache.catalina.tribes.io.BufferPool15Impl
06/11/2013 9:56:14 PM org.apache.catalina.ha.session.DeltaManager getAllClusterSessions
INFO: Manager [localhost#/manager], requesting session state from org.apache.catalina.tribes.membership.MemberImpl[tcp://ip-172-31-13-12:4000,ip-172-31-13-12,4000, alive=0, securePort=-1, UDP Port=-1, id={0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 }, payload={}, command={}, domain={112 117 98 108 105 115 104 45 99 ...(15)}, ]. This operation will timeout if no session state has been received within 60 seconds.
06/11/2013 9:56:14 PM org.apache.catalina.ha.session.waitForSendAllSessions
INFO: Manager [localhost#/manager]; session state send at 11/6/13 9:56 PM received in 143 ms.
We can see ip-172-31-13-11 adding ip-172-31-13-12 to the cluster and sending the session information via DeltaManager.
After logging to the manager app the following screen shots of the sessions on both nodes confirm the replication has been successful.
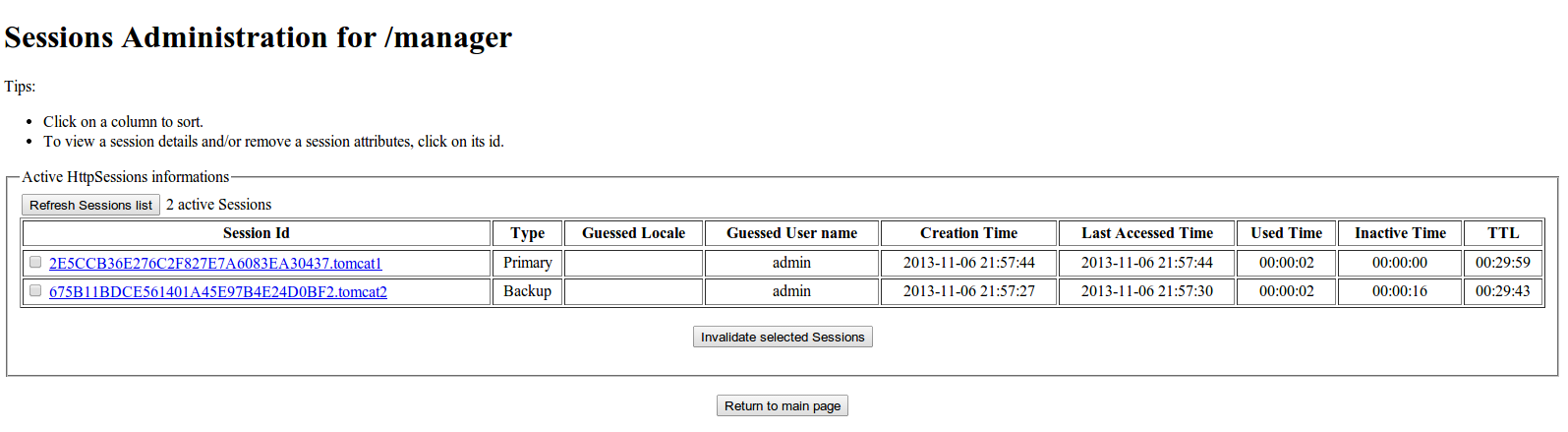
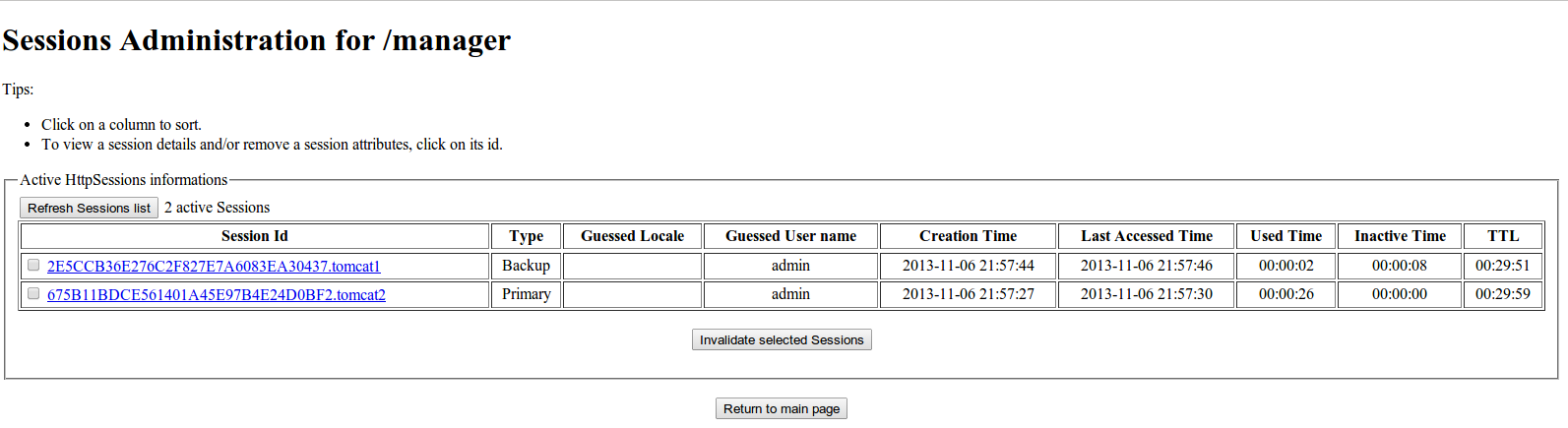
We can see that each server has created additional backup session from the other cluster member.
Considerations
Not being able to use Multicast between the availability zones imposes significant problem to Auto Scaling in case of clustering. There is no way to know before hand how many members will be in the cluster and the IP/DNS names of the additionally launched instances in event of auto scaling. This makes it very hard to configure the cluster with Auto Scaling feature and static membership. In this case, when Auto Scaling is imperative, the best option we are left with is a shared session persistent storage. I have done some testing with Shared File system, MongoDB, MySQL and Memcached (more on this is another post) as session persistent storage and they have all proved to work well. In this case though the session storage HA and the storing speed need to be taken in consideration. The store needs to be clustered or replicated and upon changes the session state needs to be flushed to the storage as soon as possible to avoid loosing it in case of server outage. Also compared to the in-memory replication in case of clustering, there will be some delays between the session changes on the primary node (where the session gets created) and the time the other server nodes get updated so the sticky sessions on the LB’s will have to stay on.



Leave a Comment