
Kubernetes cluster step-by-step: FlannelD
The purpose of this exercise is to create local Kubernetes cluster for testing deployments. It will be deployed on 3 x VMs (Debian Jessie 8.8) nodes which will be Master and Worker nodes in same time. The nodes names will be k8s01 (192.168.0.147), k8s02 (192.168.0.148) and k8s03 (192.168.0.149). All work is done as root user unless otherwise specified. Each node has the IPs, short and FQDN of all the nodes set in its local hosts file.
Before starting I decide on following Variables for Kubernetes setup:
POD_NETWORK=100.64.0.0/16
SERVICE_CLUSTER_IP_RANGE="100.65.0.0/24"
KUBE_DNS="100.65.0.10"
MASTER_IP="192.168.0.150"
CLUSTER_NAME="k8s.virtual.local"
CLUSTER_NON_MASQUEARADE_CIDR="100.64.0.0/15" # both cluster and service CIDR range
K8S_SERVICE_IP=100.65.0.1 # The IP address of the Kubernetes API Service. The K8S_SERVICE_IP will be the first IP in
# the SERVICE_IP_RANGE. The first IP in the default range of 100.65.0.0/24 will be 100.65.0.1.
K8S_SERVICE_DNS="k8s-api.virtual.local"
I also make sure I have the Kubeconfig file generated (done in Part2 of this series) for each service I’m going to run under Systemd that I can place at /var/lib/<kube-service>/kubeconfig.
FlannelD
Now that we have the Etcd cluster up and running we can move to setting up the K8S cluster overlay network. I decided to go with FlannelD for this purpose. The following image describes best the network layout and traffic flow provided by Flannel:
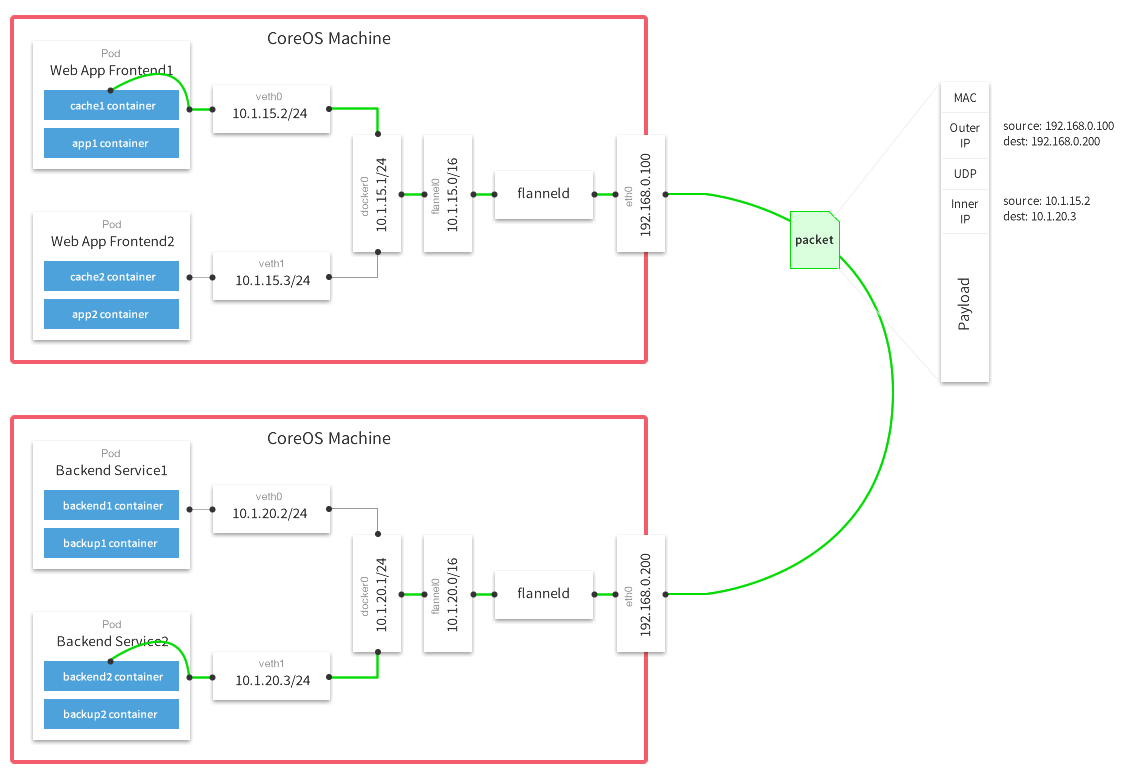
We start with creating the FlannelD configuration in etcd which FlannelD uses as backend storage.
Option 1: Run as Systemd service
On one of the nodes we run:
etcdctl set /coreos.com/network/config '{ "Network": "100.64.0.0/16", "SubnetLen": 24, "Backend": {"Type": "vxlan"} }'
Then we download and install the binary, repeat the bellow procedure on each of the nodes:
wget https://github.com/coreos/flannel/releases/download/v0.7.0/flanneld-amd64 && \
chmod +x flanneld-amd64 && \
cp flanneld-amd64 /usr/local/bin/flanneld && \
mkdir -p /var/lib/k8s/flannel/networks
We start with a test run:
root@k8s01:/usr/src# ./flanneld-amd64
I0708 14:32:55.236708 29922 main.go:132] Installing signal handlers
I0708 14:32:55.239133 29922 manager.go:136] Determining IP address of default interface
I0708 14:32:55.239769 29922 manager.go:149] Using interface with name eth0 and address 192.168.0.147
I0708 14:32:55.239807 29922 manager.go:166] Defaulting external address to interface address (192.168.0.147)
I0708 14:32:55.396233 29922 local_manager.go:179] Picking subnet in range 100.64.1.0 ... 100.64.255.0
I0708 14:32:55.403934 29922 manager.go:250] Lease acquired: 100.64.52.0/24
I0708 14:32:55.404833 29922 network.go:58] Watching for L3 misses
I0708 14:32:55.404865 29922 network.go:66] Watching for new subnet leases
We can see flanneld setting the node network:
root@k8s01:~# ip -4 addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.0.147/24 brd 192.168.0.255 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.0.150/32 scope global eth0
valid_lft forever preferred_lft forever
6: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
inet 172.17.0.1/16 scope global docker0
valid_lft forever preferred_lft forever
7: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default
inet 100.64.52.0/32 scope global flannel.1
valid_lft forever preferred_lft forever
and the flannel.1 VxLAN device created. If we check this VTEP (VxLAN Tunnel End Point) device:
root@k8s01:~# ip -4 -d link show flannel.1
3: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN mode DEFAULT group default
link/ether 7a:a8:2d:9f:4f:09 brd ff:ff:ff:ff:ff:ff promiscuity 0
vxlan id 1 local 192.168.0.147 dev eth0 srcport 32768 61000 dstport 8472 nolearning ageing 300
we can see the VxLAN specifics, like the VNI (VxLAN Network Identifier) that plays a role when scaling up the network for multitenancy, the eth0 device and the ip the tunnel will go through for peer communication, the UDP port 8472 used and the nolearning tag that disables source-address learning meaning Multicast is not used (since it is not even enabled on some providers like AWS) but Unicast with static L3 entries for the peers which we can see in the device FDB populated by Flannel:
root@k8s01:~# bridge fdb show dev flannel.1
de:a5:af:80:d3:db dst 192.168.0.148 self permanent
ae:ea:b6:88:72:39 dst 192.168.0.149 self permanent
The Flannel daemon also emulates the ARP protocol and populates the host ARP table according to the kernel requests via the L2/L3 MISS notification mechanism. When a container sends a packet to a new IP address on the flannel network (but on a different host) this generates a L2 MISS (i.e. an ARP lookup). When the host encapsulates the packet in order to be sent to another host on the network the kernel vxlan code generates a call to the flannel daemon to get the public IP that should be used for that VTEP (this gets called an L3 MISS). The v2.x of flannel vxlan removed the need for the L3 MISS callout. When a new remote host is found (either during startup or when it’s created), flannel simply adds the required entries so that no further lookup/callout is required.
For more in depth overview of VxLAN, its options and tunneling types I highly recommend the following post by Vincent Bernart VXLAN & Linux.
The daemon had also created the following config file:
root@k8s01:/usr/src# cat /var/run/flannel/subnet.env
FLANNEL_NETWORK=100.64.0.0/16
FLANNEL_SUBNET=100.64.52.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=false
and installed some routes on the node:
root@k8s01:/srv/kubernetes# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.0.1 0.0.0.0 UG 0 0 0 eth0
100.64.0.0 0.0.0.0 255.255.0.0 U 0 0 0 flannel.1
100.64.52.0 0.0.0.0 255.255.255.0 U 0 0 0 docker0
192.168.0.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
that are used for routing the container traffic. We can see that the containers on the same host communicate to each other over the docker0 linux bridge (each container gets its own network namespace which gets connected to docker0 bridge via pair of veth interfaces) and the traffic to the containers on the other nodes will go via flannel.1 interface as per the routing rule for the 100.64.0.0/16 subnet.
Now that we are confident all is working properly we install the systemd unit file:
cat << EOF > /lib/systemd/system/flanneld.service
[Unit]
Description=Network fabric for containers
Documentation=https://github.com/coreos/flannel
After=network.target
After=network-online.target
Wants=network-online.target
After=etcd.service
Before=docker.service
[Service]
Type=notify
Restart=always
RestartSec=5
ExecStart=/usr/local/bin/flanneld \\
-etcd-endpoints=http://192.168.0.147:4001,http://192.168.0.148:4001,http://192.168.0.149:4001 \\
-logtostderr=true \\
-ip-masq=true \\
-subnet-dir=/var/lib/flanneld/networks \\
-subnet-file=/var/lib/flanneld/subnet.env
[Install]
WantedBy=multi-user.target
EOF
Make sure you have ip-masq set to true so Flannel can add the necessary iptables rules to NAT the outgoing “public” traffic or the Kubernetes services Pods will not have cluster outbound access thus no DNS resolution for public domains which means no internet access. If we set this option to true we must make sure that the same is set to false for the Docker engine.
By default Flannel uses the default route interface, in this case eth0, for its uplink. In case we have multiple network interfaces with IP’s on the same LAN segment or we have multiple IP’s on eth0 then we should also specify:
-interface=eth0
-public-ip=192.168.0.147
to avoid confusion and Flannel picking up a wrong interface and IP for its uplink.
Start and enable the service:
systemctl daemon-reload
systemctl enable flanneld
systemctl start flanneld.service
systemctl status -l flanneld.service
Option 2: Run as CNI plug-in in Kubernetes
TODO
Docker integration
We need to integrate Docker docker0 bridge with Flanneld network. This is mine /etc/systemd/system/docker.service unit service file:
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target docker.socket flanneld.service
Wants=network-online.target
Requires=docker.socket
[Service]
Type=notify
#Environment=DOCKER_OPTS="--bridge=docker0 --iptables=false --ip-masq=false --ip-forward=true --log-driver=json-file --mtu=1450"
# FlannelD subnet setup
EnvironmentFile=/var/lib/flanneld/subnet.env
# the default is not to use systemd for cgroups because the delegate issues still
# exists and systemd currently does not support the cgroup feature set required
# for containers run by docker
ExecStart=/usr/bin/dockerd --bip=${FLANNEL_SUBNET} --mtu=${FLANNEL_MTU} --iptables=false --ip-masq=false --ip-forward=true --log-driver=json-file --log-level=warn --log-opt=max-file=5 --log-opt=max-size=10m --storage-driver=aufs -H fd://
ExecReload=/bin/kill -s HUP $MAINPID
LimitNOFILE=1048576
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
LimitNPROC=infinity
LimitCORE=infinity
# Uncomment TasksMax if your systemd version supports it.
# Only systemd 226 and above support this version.
#TasksMax=infinity
TimeoutStartSec=0
# set delegate yes so that systemd does not reset the cgroups of docker containers
Delegate=yes
# kill only the docker process, not all processes in the cgroup
KillMode=process
# restart the docker process if it exits prematurely
Restart=on-failure
StartLimitBurst=3
StartLimitInterval=60s
MountFlags=shared
[Install]
WantedBy=multi-user.target
and the Docker socket unit file /etc/systemd/system/docker.socket:
[Unit]
Description=Docker Socket for the API
PartOf=docker.service
[Socket]
ListenStream=/var/run/docker.sock
SocketMode=0660
SocketUser=root
SocketGroup=docker
[Install]
WantedBy=sockets.target
Now we restart Docker:
systemctl stop docker.service
iptables -t nat -F
ip link set docker0 down
systemctl start docker.service
systemctl is-enabled docker.service || systemctl enable docker.service
And now we have:
root@k8s01:/usr/src# ip -4 addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.0.147/24 brd 192.168.0.255 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.0.150/32 scope global eth0
valid_lft forever preferred_lft forever
6: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
inet 100.64.52.1/24 scope global docker0
valid_lft forever preferred_lft forever
7: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default
inet 100.64.52.0/32 scope global flannel.1
valid_lft forever preferred_lft forever
So docker0 bridge got the first IP of the Flanneld subnet which for this host is 100.64.52.1/24.
References
This article is Part 4 in a 8-Part Series Kubernetes cluster step-by-step.
- Part 1 - Kubernetes cluster step-by-step: Nodes System Setup
- Part 2 - Kubernetes cluster step-by-step: Binaries, Certificates, Kubeconfig and Tokens
- Part 3 - Kubernetes cluster step-by-step: ETCD
- Part 4 - This Article
- Part 5 - Kubernetes cluster step-by-step: Kube-apiserver with Keepalived and HAProxy for HA
- Part 6 - Kubernetes cluster step-by-step: Kubelet, Kube-scheduler and Kube-controller-manager
- Part 7 - Kubernetes cluster step-by-step: Kubernetes Add-ons
- Part 8 - Kubernetes cluster step-by-step: Services and Load Balancing
Leave a Comment